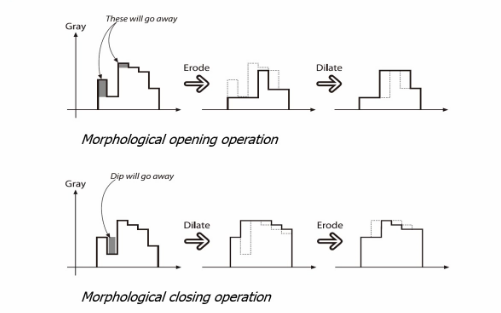
[Image Processing] 구조적 요소(Structuring Element) 및 팽창, 침식, 닫힘, 열림 연산
수학적 형태학이란? 수학적 형태학(Mathematical Morphology, MM)은 집합론, 격자론, 위상수학 그리고 무작위 함수에 기반한 기하학적 구조를 분석하고 처리하는 이술과 기론이다. 이는 대부분 디지털 이미지에 적용되지만, 그래프, 폴리곤 메시, 솔리드, 그리고 많은 공간 구조에도 적용할 수 있다. 크기, 모양, 블록성, 연결성 그리고 지오데식 거리 같은 위상수학적 그리고 기하학적 연속 공간 개념은 MM에 의해서 연속 공간과 이산 공간 모두에서 소개되었다. 또한 이미지를 위의 특성화에 따르도록 이미지를 변환하는 연산의 집합으로 이루어진 형태학적 디지털 화상 처리의 근본이다. 구조적 요소란? 구조적 요소란 원본 이미지에 적용되는 커널(Kernel)이라고 할 수 있는데, 수학적 형태학에서 구조적..
2020.11.14