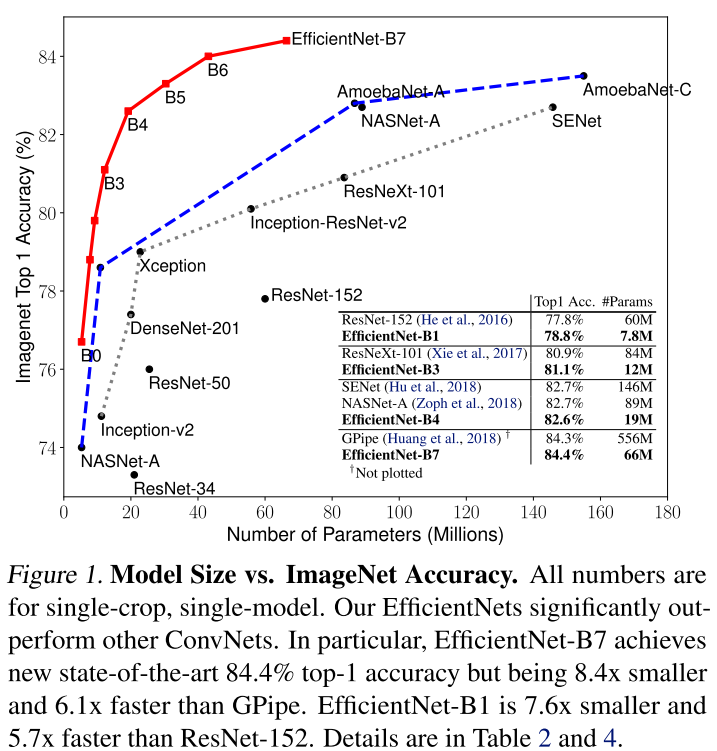
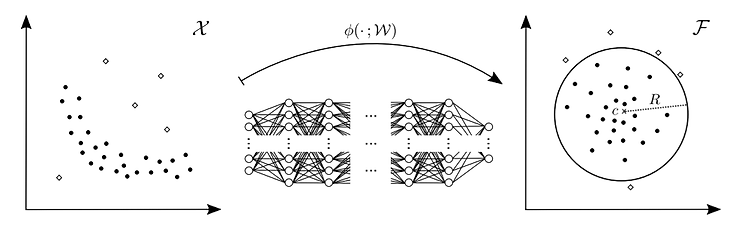
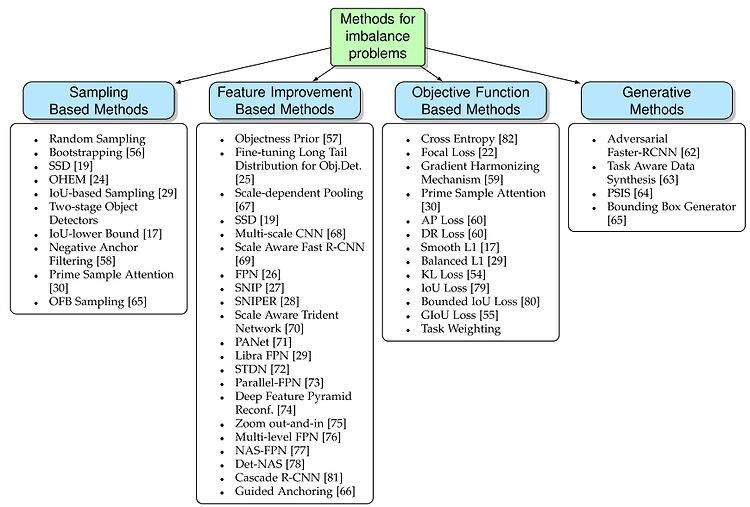
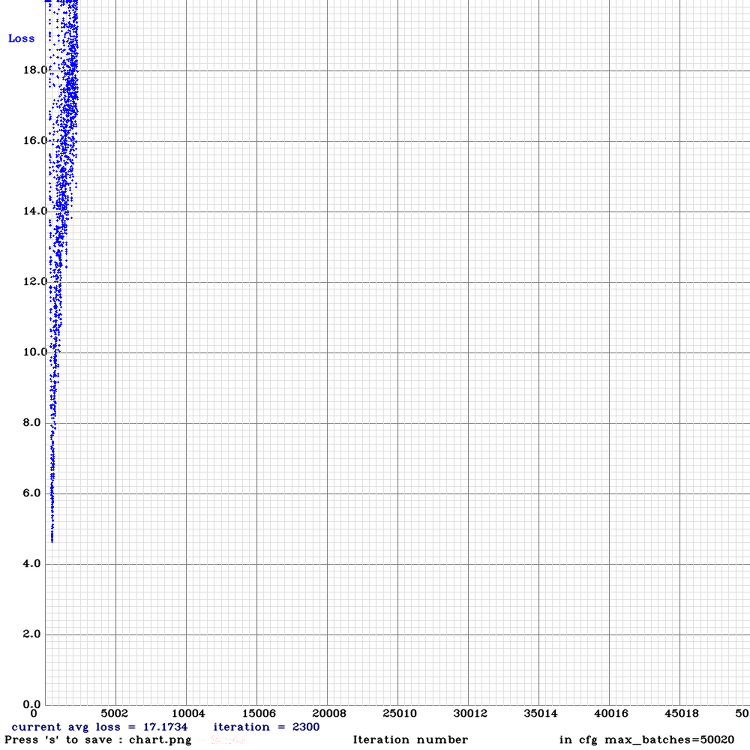
[Video Surveillance] 영상 감시 분야에서 이상 탐지(Anomaly Detection)
영상감시(Video Surveillance) 분야에서는 CCTV 영상에서 사람의 비정상적인 행위를 탐지하거나, 사물의 비정상 상황을 인식하는 일이 중요하다. 예를 들어, 고속도로에서 차량 전복 사고가 일어나거나, 어린이 보호구역 보행로에 자전거 및 차량 출현 또는 지하철역에서 싸움 등이 발생하는 비정상(Abnomal) 케이스들을 탐지하여 사고를 예방하거나, 사고에 대한 적절한 대응을 해야한다. 이상 탐지(Anomaly Detection) 기술은 사실 오래전부터 연구되어왔던 분야이다. 이는 영상감시 분야 뿐만 아니라, 머신비전(Machine Vision) 분야에서 장비로부터 측정된 시계열 데이터를 기반으로 한 고장 예측, 제품 결함 검사 등 다양한 환경에 접목 될 수 있다. 1. 이상 탐지(Anomaly ..
2020.02.21