[SQLD] 8. 반정규화와 성능
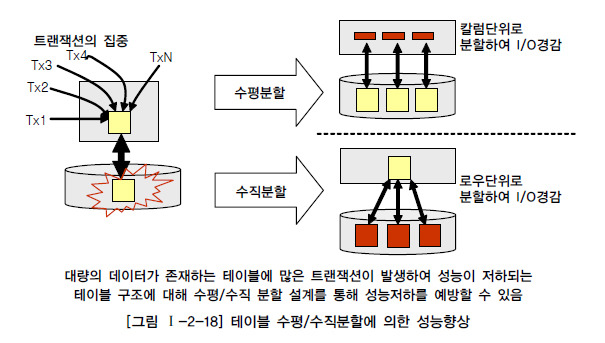
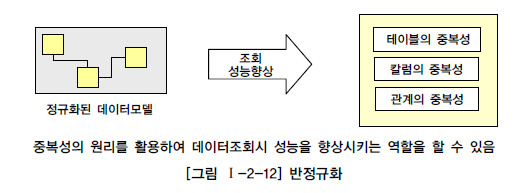
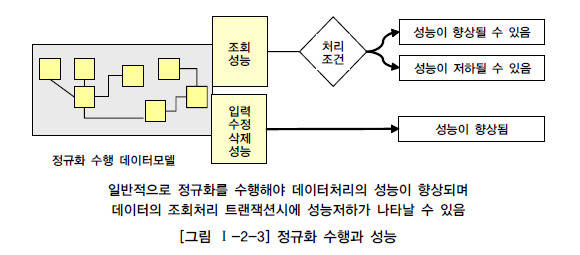
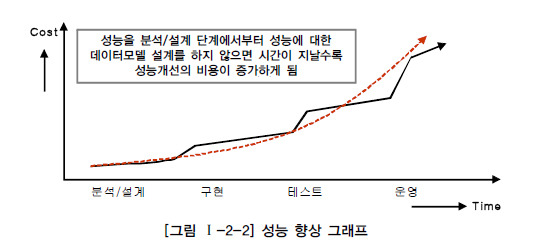
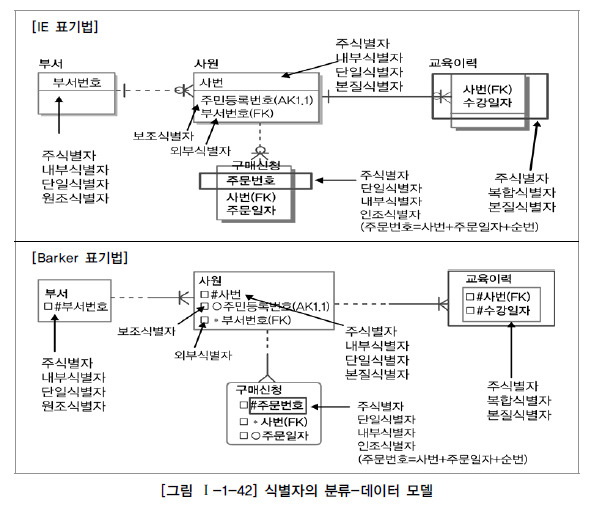
제 3절 반정규화와 성능 1. 반정규화를 통한 성능향상 전략 가. 반정규화의 정의 반정규화(=역정규화, De-Normalization)는 정규화된 엔티티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델리의 기법을 의미한다. 즉, 데이터를 중복하여 성능을 향상시키는 기법이며, 더 넓은 의미의 반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정을 포함하게 된다. 데이터 무결성이 깨질 수 있는 위험성이 있는 반정규화를 적용하는 이유는 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이..
2016.08.04