[SQLD] 13. DDL(Data Definition Language)
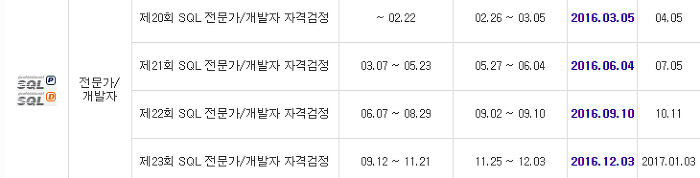
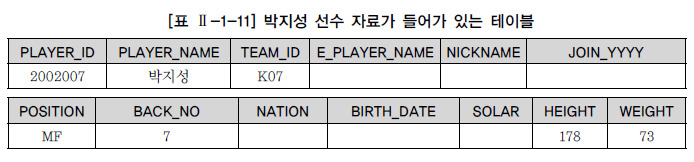
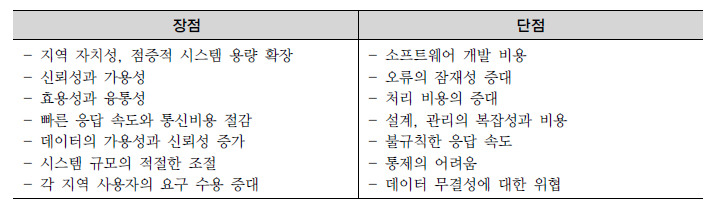
제 2절 DDL(Data Definition Language) 1. 데이터유형 - 데이터베이스의 테이블에 특정 자료를 입력할 때, 그 자료를 받아 들일 공간을 자료의 유형별로 나누는 기준- 선언한 유형이 아닌 다른 종류의 데이터가 들어오려고 하면 데이터베이스는 에러 발생 - ANSI / ISO 숫자타입 : NUMERIC Type의 하위개념인 NUMERIC, DECIMAL, DEC, SMALLINT, INTGER, INT, BIGINT, FLOAT, REAL, DOUBLE PRECISION- SQL Server, Sybase 숫자타입 : 작은 정수형, 정수형, 큰 정수형, 실수형, MONEY, SMALLMONEY 등- Oracle 숫자타입 : NUMBER- ANSI / ISO 그 외 데이터타입 : Bina..
2016.08.11