[Book Review] ChatGPT 책 추천 - 인공지능 전문가가 알려 주는 챗GPT로 대화하는 기술
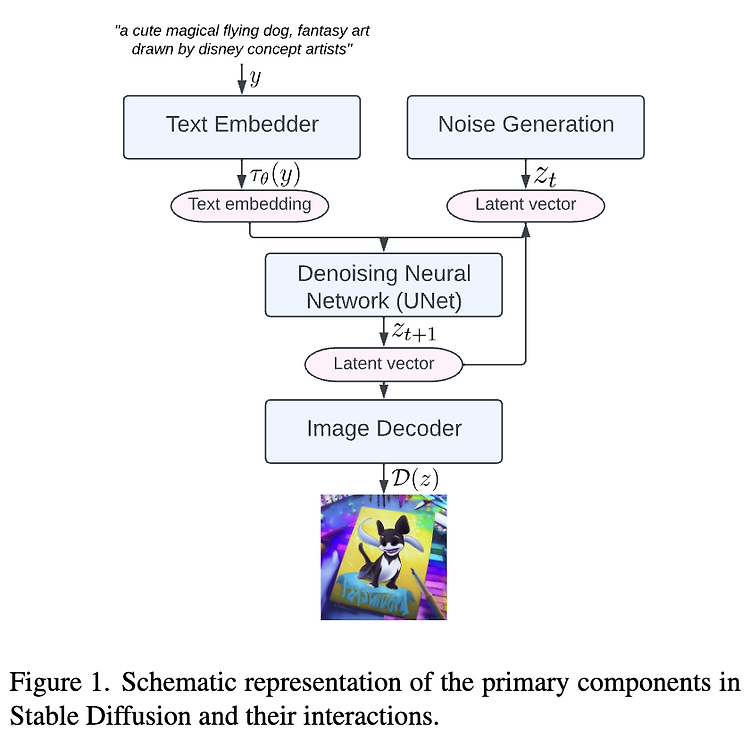
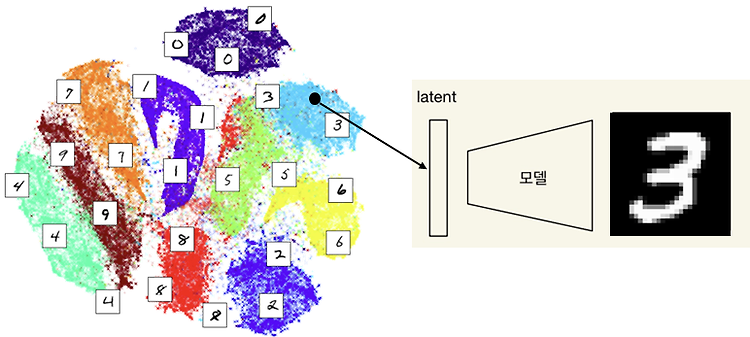
인공지능을 개발하는 입장에서 요즘 느끼는 것은 인공지능이 예전보다 훨씬 대중화 되었고, 인공지능을 개발하거나 서비스를 만드는데 있어서 진입장벽이 훨씬 낮아졌다는 생각이 많이 든다. 그 이유는 바로 ChatGPT, Diffusion 기술 때문이다. ChatGPT 또는 Diffusion 기술들을 이용하여 서비스를 만들거나 창작물을 만들어 낼 때 전문가만큼의 지식이나 기술, 배경, 원리를 알지 못하더라도 서비스를 사용하거나 직접 만들어낼 수 있는 세상이 왔다. 어쩌면 앞으로는 이러한 기술의 원리를 알지 못하더라도 서비스를 사용하는데 상관없어지지 않을까 싶다. 개인적인 생각으로는 물론 엔지니어 입장에서 기술의 배경을 아는 것과 모르는 것의 차이는 크다고 생각하고, 아는 것이 필요하다고 생각하지만, 결국 이런 기..
2023.07.20